
Bir önceki yazıda C# ile Smote algoritmasını incelemiştik (Açılımı Synthetic Minority Oversampling Technique'dir). Algoritma azınlık durumda olan sınıfların sayısını sentetik değerler üreterek çoğunluk olan sınıfın adedine dengelemeye yardımcı olmaktadır.
Bir önceki yazıda algoritmanın ince detaylarından bahsetmiştik. Kısa bir tekrar yapmak gerekirse. Azınlık durumunda olan örnekler tek tek geziliyor her bir örneğe en yakın sayıda olan n adet diğer örneklerden bir tanesi rastgele seçiliyordu. Bu iki nokta arasında kalan mesafe içinde rastgele istenen miktara uygun oranda yeni noktalar üretiliyordu.
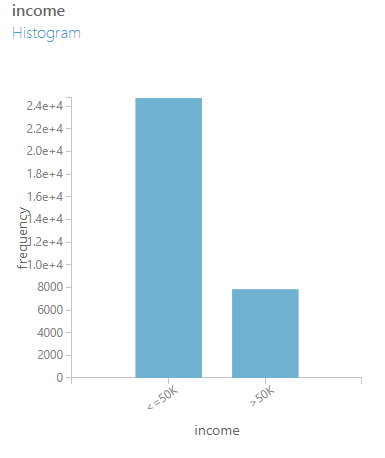
Şimdi bunu Azure ML Studio üzerinde nasıl yapacağımıza bakalım. Denemek için hazır verilerden "Adult Census Income Binary Classification dataset" kullanarak başlayacağız. Bu veride ">50K" sınıfına ait verilerde bariz azlık var.
Bunu dengelemek için SMOTE kutucuğunu tuvale bırakacağız görünüm aşağıdaki gibi olacak.
Öncelikle küçük ayarlamalar yapmak gerekecek.
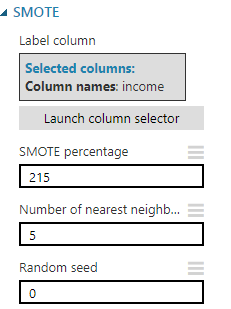
Label Column etiket kolonunun hangisi olduğunu buradan söylememiz gerekiyor. Bu veriseti için bu "income" olacak. Modül azınlıkta olan sınıfı kendisi otomatik olarak bulacak. Burada önemli olan husus, etiket niteliğinin ikili olması zorunluluğu.
SMOTE Percentage azınlık durumundaki sınıftan ne oradan sentetik örnekler üretileceğini soruyor.
Number of nearest neighbors her nokta için seçilecek rastgele noktanın ne kadar uzağa kadar seçileceğini ayarlamanızı sağlıyor. Cümle anlamsız geldisyse bir önceki yazıya şöyle bir bakın.
Random seed, algoritmamız rastgelelik içerdiğinden her çalıştırdığımızda farklı değerler üretecektir. Bu da test etmemizi engelleyecektir. Bunun önüne geçmek için buraya yazacağımız bir tohum değeri sürekli aynı değerlerin üretilmesini sağlayacaktır.
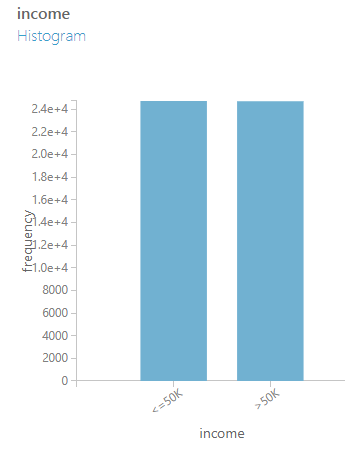
Örneğimizi çalıştırdığımızda artık verilerimizin dağılımı şu şekilde olacaktır:
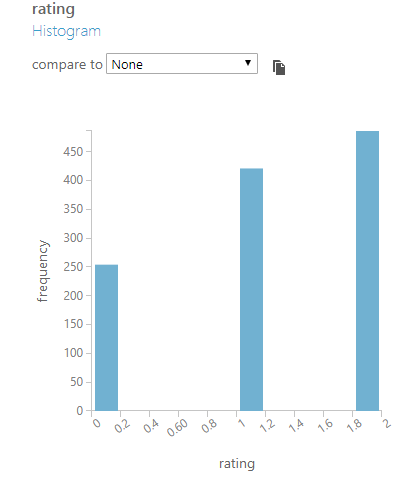
Etiket kolonu kısmında kendisinin sadece ikili "binary" sınıflar için çalıştığını söylemiştim. Ya verimizde 2 den fazla sınıf varsa? Sınıflar arasındaki dengeyi SMOTE kullanarak nasıl kurabiliriz? Bir çok farklı yöntem uygulanabilir, örneğin veriyi en kalabalık sınıfla birlikte 2li şekilde gruplayıp ve her grup için SMOTE çalıştırabiliriz.Bu yöntemi örnekleyelim. Yine Azure ML Studio ile birlikte gelen veri setlerinden olan "Restaurant ratings" verilerini kullanacağız. Bu veri setindeki başlangıç dağılımı şu şekildedir:
Gruplama işlemleri için Python desteğini kullanacağız. Tuval aşağıdaki gibi oluşacak.
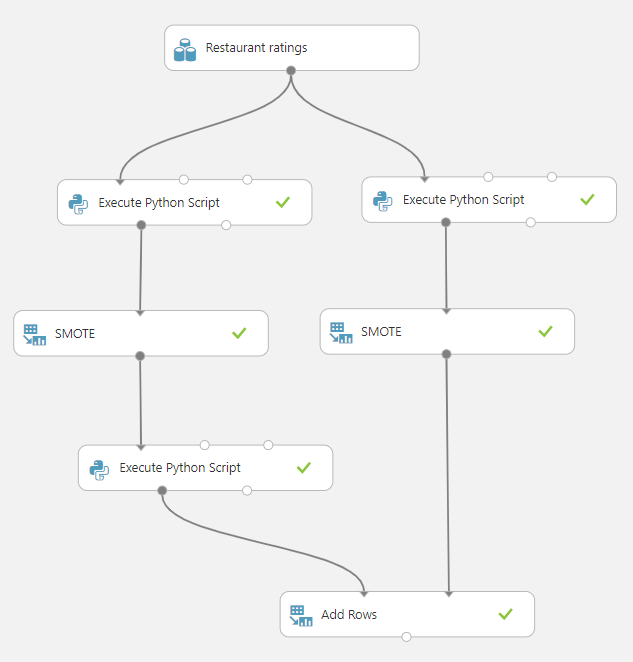
Sol üsten başlayarak sırasıyla çalıştıracağımız scriptler ise şu şekilde:
Sol üst köşe için, 1 olmayan sınıfları getir.
def azureml_main(dataframe1 = None, dataframe2 = None):
filter = (dataframe1["rating"] != 1 )
return dataframe1[filter],Sağ üst köşe için 0 olmayan sınıfları getir.
def azureml_main(dataframe1 = None, dataframe2 = None):
filter = (dataframe1["rating"] != 0 )
return dataframe1[filter],Sol alt için, 2 olmayan sınıfları getir.
def azureml_main(dataframe1 = None, dataframe2 = None):
filter = (dataframe1["rating"] != 2 )
return dataframe1[filter],SMOTE kutularınada sırasıyla 91 ve 15 değerlerini veriyoruz. Çünkü en kalabalık olan 2 numaralı sınıftan elimizde 486 örnek var. 1 numaralı sınıftan ise 254 örnek var. \left(\frac{486}{254} -1\right) * 100 orantısıyla 1 numaralı sınıf için girmemiz gereken değerin 91 olduğunu buluyoruz. Aynı mantığı 421 eleman içeren diğer sınıfa da uyguluyoruz ve 15 buluyoruz.
Son olarak "Add Rows" modülü ile sonuçları birleştiriyoruz. Neticede dağılım grafiğimiz şöyle olacak:
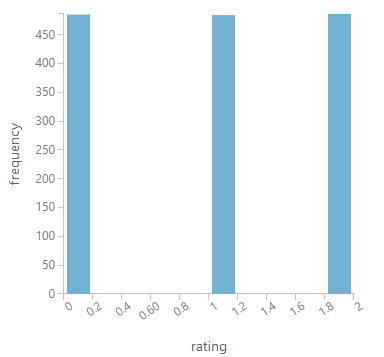
Yeni yazılarda görüşmek üzere.
